Full-Body Pose


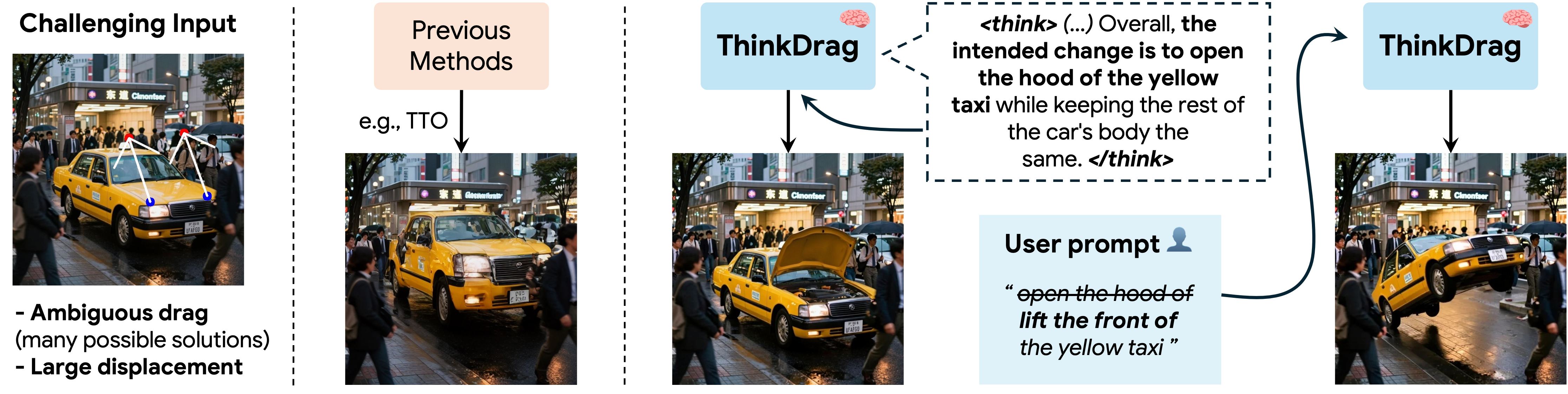
Drag-based image editing provides an intuitive interface for spatially controlled image manipulation by allowing users to specify handle and target points. Existing methods have made substantial progress through optimization-based, guidance-based, and feed-forward formulations, but they often interpret drag instructions as geometric displacements. This limits their effectiveness when the desired edit depends on interpreting image content and inferring a plausible semantic transformation from sparse point constraints.
We introduce ThinkDrag, a unified multimodal framework for drag-based image editing with visual reasoning. ThinkDrag is trained to associate point constraints with meaningful object- and scene-level transformations, and can optionally follow an explicit reasoning path that interprets the intended edit before image generation. This reasoning path improves interpretability and is especially useful for challenging ambiguous cases where the same drag instruction may admit multiple plausible edits.
To support this framework, we construct a supervised dataset of semantic drag transformations paired with reasoning traces and introduce DragBench++, a benchmark targeting challenging drag-based editing scenarios with reference edit solutions. Experiments show that ThinkDrag achieves state-of-the-art performance, improving generation quality and plausibility while maintaining competitive point-following precision.
Starting from synthetic image pairs, the pipeline filters implausible edits, matches semantic keypoints, and creates reasoning chains that explain how each drag maps to the intended transformation.
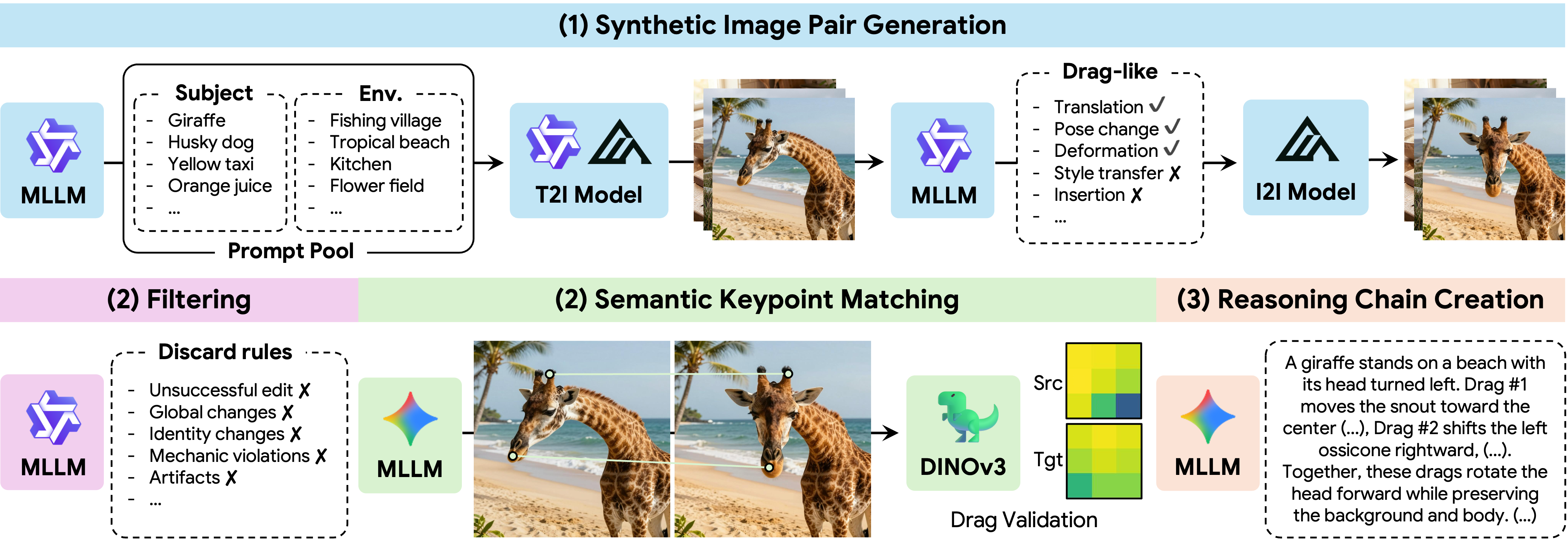
The resulting dataset covers diverse transformation types, including pose, gaze, object motion, resizing, deformation, and rotation.













ThinkDrag represents drag instructions through structured text tokens and spatial endpoint markers in a unified multimodal model, then generates edits directly or after producing a reasoning trace that interprets the edit intent.

Each row compares the same input and drag handles across competing drag-based image editing methods.

















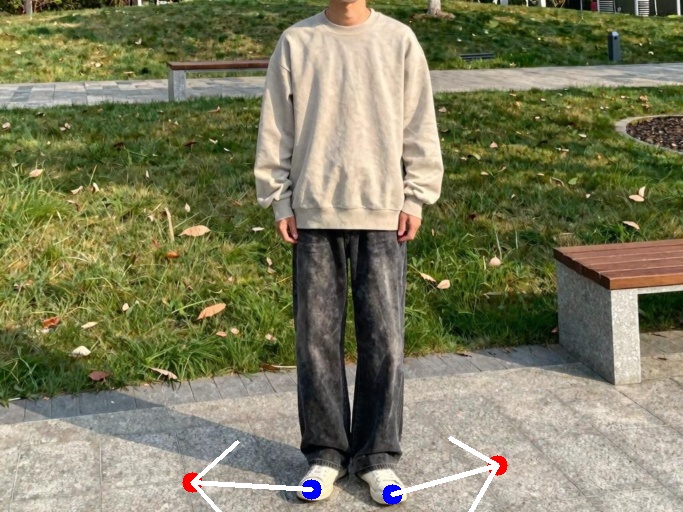

















ThinkDrag first infers the intended edit from the handles, then uses that thinking trace to guide generation.
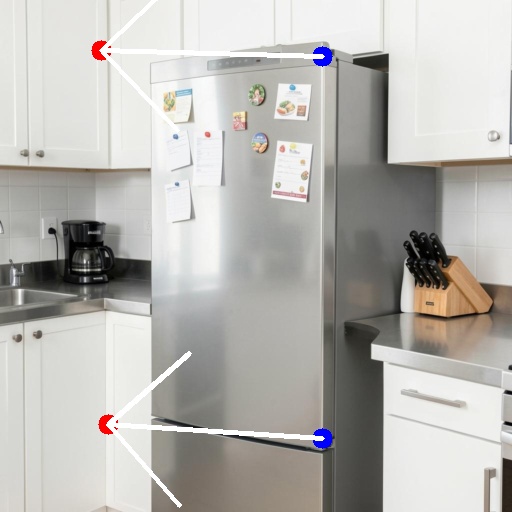

Drag #1 pulls the top-right corner of the refrigerator door horizontally to the left.
Drag #2 shifts the bottom-right corner of the door to the left.
Because both act on the right edge of the same door, they work together to swing the door open along its left-side hinge.



Drag #1 lifts the front of the hood from its resting position up to an open angle.
Drag #2 pulls the upper edge of the hood upward, ensuring the entire panel tilts naturally.
Because both act on the taxi hood, they work together to transition the vehicle from a closed state to an open one.



Drag #1 pulls the crest of a wave on the left side of the painting upward.
Drag #2 shifts a prominent wave on the right side of the sea upward toward the top.
Because both move foam in an ascending direction, they create the appearance of a taller, more dramatic breaking wave.

The same handles can lead to different edits when the drag instruction is paired with different user text prompts.






TBD